빅데이터 관련 학습노트 - 01 - 머신러닝 개요 및 데이터전처리
SK 동반성장아카데이 내 '머신러닝의 이해와 실습' 강의 정리

1. 정리
1.1. 머신러닝이란?
-
기계 즉 컴퓨터가 주변의 환경에서 발생하는 데이터를 학습하여 유의미한 패턴과 통계적인 함수를 발견하여 앞으로의 행동의 지침이 되는 지식을 얻어내는 행위
1.2. 머신러닝의 3가지 방법론
| 감독학습 |
target 값이 있는 데이터인 경우 |
| 비감독학습 |
target 값이 없는 데이터인 경우 |
| 강화학습 |
게임의 agent가 스스로 정답이나 목표를 찾아가도록 학습하는 과정 |
1.3. 머신러닝 알고리즘의 범주
-
회귀
-
분류
-
추천
-
대체
1.4. 데이터 전처리 작업
-
데이터 멍밍(Munging)
-
랭글링(Wrangling)
-
Missing Data 처리
-
Outlier 처리 등
2. 머신러닝 개요
2.1. 개요
컴퓨터가 데이터를 통해 유의마한 패턴과 통계적인 함수를 발견하여 행동의 지침이 되는 지식을 얻어내는 행위
2.2. 활용사례
아래 그림은 업계에서 많이 쓰이는 방법론
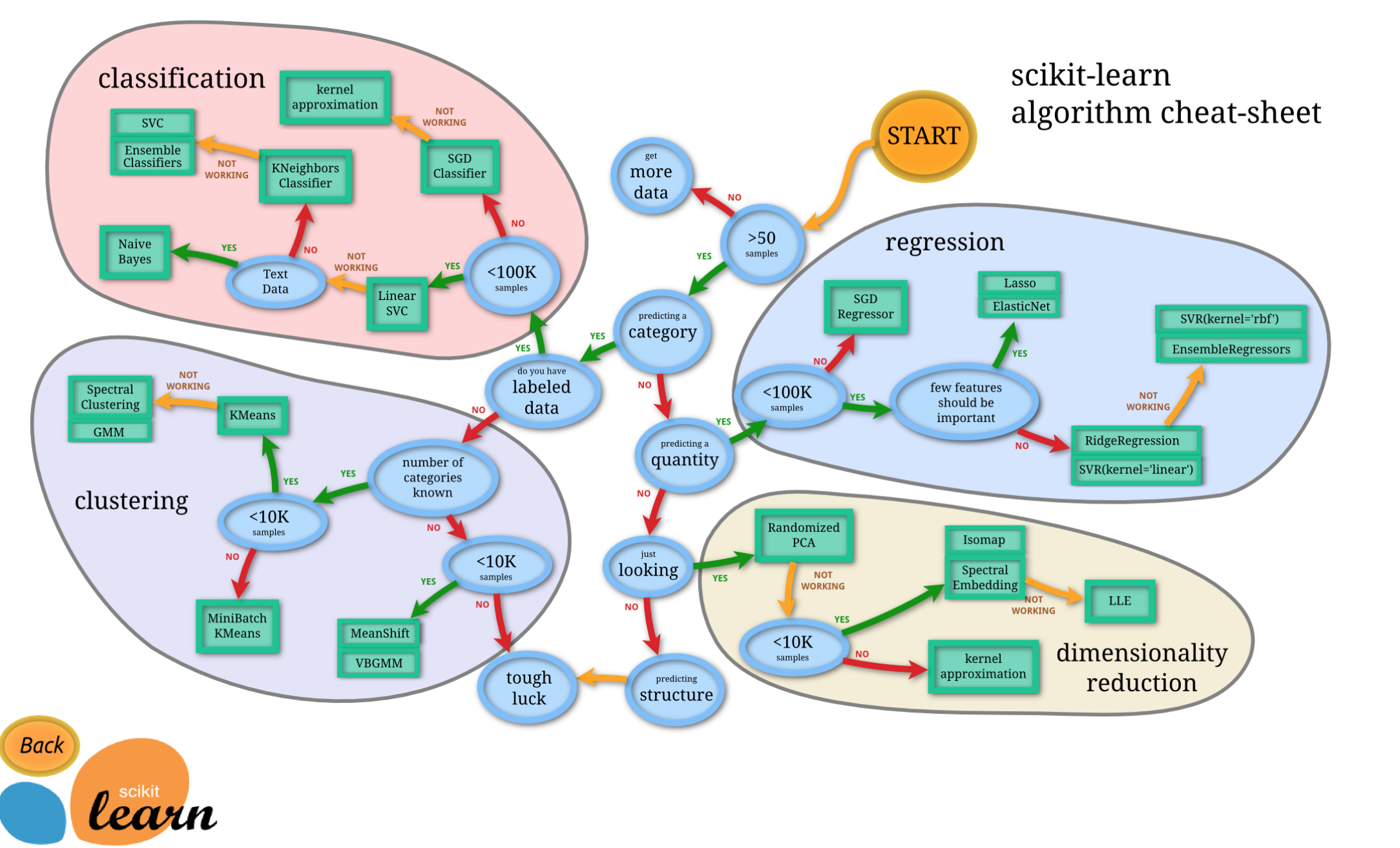
2.2.1. 회귀
입력데이터를 바탕으로 원하는 타겟변수의 미래결과 예측 (타겟변수는 범주형데이터나 연속현데이터든 상관하지 않음)
-
통계학의 지식을 많이 활용
-
회귀분석/다변량통계학/시계열분석등 활용
활용예시
| 금융분야 |
주식시장 예측, 환율예측, 상품 risk예측 등 |
| CRM |
백화점 수요예측, 가격견적, 광고입찰, 고객의 쿠폰반응 예측 등 |
2.2.2. 분류
입력데이터를 바탕으로 개별 데이터의 부류(Class)를 예측하거나 계급 결정 (타겟변수는 주로 범주형 데이터 활용)
활용예시
-
스팸 필터링
-
신용카드 사기탐지
-
VIP 고객 여부
-
제조 결함 탐지
-
약물 효능 검사
2.2.3. 추천
고객이 선호하는 상품 혹은 그 대안 예측
활용 예시
-
홈쇼핑의 상품추천
-
넷플릭스의 영화 추천
-
유튜브의 선호영상 추천 등
2.2.4. 대체
누락된 입력데이터의 값 보강
확용 예시
-
불완전한 환자의 의료 데이터 기록 보강
-
송상된 고객 데이터 보충
-
인구조사 자료 보충 등
3. 머신러닝의 방법론
3.1. 지도학습
-
훈련 데이터 안에 예측 또는 추론해야 할 target이 있는 경우에 사용되는 방법론
3.2. 비지도학습
-
훈련 데이터 안에 예측해야할 target이 없음
-
함수모형을 만들지 않고 데이터의 패턴을 추출함
-
데이터의 숨겨진 구조를 찾음
3.3. 강화학습
-
데이터가 스스로 정답을 찾기 위해서 환경과 상호작용함
-
target 값을 만들면서 훈련하는 학습
-
해담에서 멀어질수록 벌점이 부과되는 성질 이용
-
풀려고 하는 문제를 게임으로 간주하여 적용
4. 오브젝트 디텍션
-
감독학습
-
분류
5. 머신러닝의 프로세스
머신러닝의 프로세스는 아래와 같음
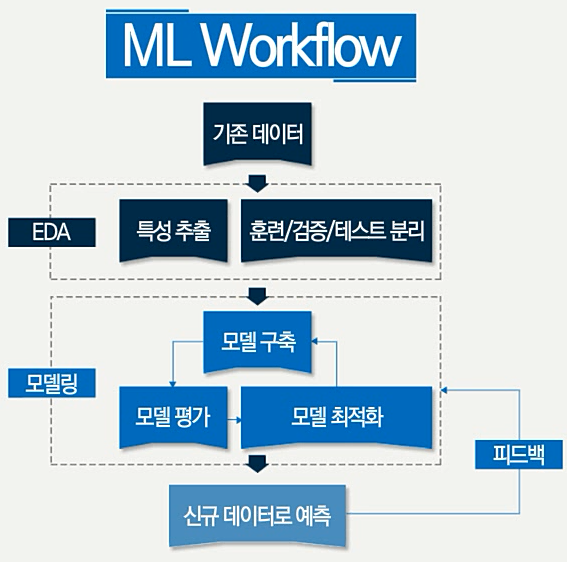
-
기존 데이터 기존의 데이터를 전처리 작업
-
EDA(Exploratory Data Analysis) 탐색적 데이터 분석(Exploratory Data Analysis)로서 머신러닝 모델을 만들기 위한 전단계로 특성을 추철하거나 데이터로서 영감을 얻거나 전반적인 패턴을 알기 위하여 통계적인 분석을 시도하는 일을 뜻함
이 후 향후에 쓰일 알고리즘을 결정하는 경우가 많음
-
특성추출 업무 분석을 통핸 현업 브레인스토밍 등
-
훈련/검증/테스트 분리 훈련 데이터와 테스트를 나눔
-
모델링
-
-
모델구축 훈련 데이터를 이용해 모델 구축
-
모델 평가 테스트 데이터를 이용해 모델 테스트
-
신규 데이터로 예측 및 피드백 실제 데이터를 이용해 모델 평가 후 부족한 부분을 보완
-
6. 머신러닝 사례
6.1. 여행119
-
고객 성별 예측
-
보유 데이터(나이, 여행보험 건수, 과거 목적지, 결혼 여부)
-
target은 지도학습이며, 범주형 데이터로 회귀분석이나 분류모델 사용
-
훈련 데이터 70% 테스트 데이터 30%
-
지도학습을 이용해 분류모델, 의사결정트리 사용
-
모델구축 → 데이터검증 → 모델평가 → 모델구축(모델갱신) → 데이터검증(데이터보강) → 모델평가(모델최적화)
6.2. 여행 경로 추천 서비스
-
고객의 성향에 맞는 여행 경로 추천
-
보유 데이터(나이, 출발지, 경유지, 선호장소)
-
유전자 알고리즘과 협업 필터링 사용
7. 머신러닝의 구현방법
-
데이터 가공 및 전처리
-
결측 데이터 처리 작업 필요(왜곡된 데이터가 잘못된 모델을 만들 수 있음)
-
결측 데이터 감지방법 : Outlier Detection 알고리즘 등
-
Outlier Detection 알고리즘은 보통 데이터의 평균적인 패턴에서 멀리 떨어져 있는 노이즈성 데이터인 아웃라이어를 디텍션하는 알고리즘
-
-
-
훈련 데이터 추출
-
모델 평가(실제값과 예측값의 비교)
-
모델의 매개변수 조정 : 특성 변수를 찾는 과정 포함
-

Twitter
Google+
Facebook
Reddit
LinkedIn
StumbleUpon
Email